
Merchants are facing an uphill challenge when it comes to CNP Fraud. While they recognize the risks and have put solutions in place to fight fraud, they are often falling short of the desired result. There is a huge financial impact associated with false declines. That’s revenue merchants are leaving on the table. And the customers they decline will frequently explore other options the next time they go shopping. Merchants may also be facing a high rate of fraud chargebacks. They know they’re taking on too much but their efforts to control the problem aren’t working. Rule-based fraud strategies always seem to be one step behind criminals. Fraud control system and chargeback management costs are going through the roof, with very little to show for it. Developing accurate and timely detection methods is essential but difficult.
An effective fraud control system must:
- Address diverse and hidden fraud behavior
- Recognize evolving fraud patterns
- Provide timely feedback
- Adjust quickly and accurately to emerging threats
- Significantly reduce false positives
 At this point, a merchant might jump to the false conclusion that an advanced machine learning system will solve every fraud challenge. On its own, that simply isn’t the case.
At this point, a merchant might jump to the false conclusion that an advanced machine learning system will solve every fraud challenge. On its own, that simply isn’t the case.
AI/ML systems have several dependencies and can fail for a variety of reasons.
- Feature engineering by experts is key to the performance of the system. Domain expertise is essential to fine tune and optimize models.
- Data quality determines the upper limit of model performance. The adage, “garbage in, garbage out” is especially valid when looking at the effectiveness of any AI/ML system. Without access to consortium data and collaborative data sharing the insight and accuracy of a model will be limited.
- Each algorithm targets a specific threat. In isolation a model will never be adequate. A cohesive strategy that provides orchestrated coverage is key.
- ML/AI is not a standalone solution and should not be expected to perform as one. Leading fraud systems leverage a wide range of technologies, including:
- AI/ML
- Consortium data
- Graph link analysis
- Advanced identity authentication
- Silent pending
- And more…


AutoML -Machine Learning Pipeline Automation
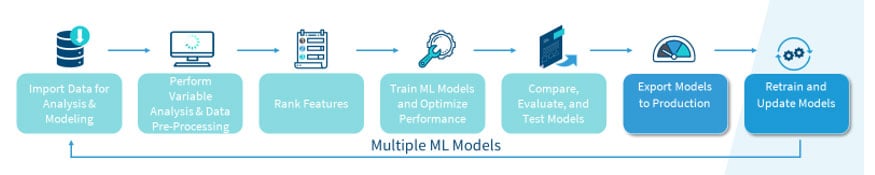
Before this pipeline concept, to train a machine learning model, data scientists need to go through a complex process which contains multiple steps:
- Import data from data warehouse
- Perform variable analysis to exam distributions
- Perform data transformation to transform data into a format that suitable for the proposed algorithm
- Select only a subset of variables which are most useful to reduce calculation burden
- Train multiple models by tuning the hyper parameters
- Proceed model evaluation and comparison to chose best model.
- Deploy model to production.
Data scientist used to go through this process manually and repeat this process many times to train one model.
Vesta built a ML pipeline platform to standardize the model training process and improve its efficiency. The pipeline contains each of these steps as building block. Data scientist can build models by modifying a configuration file to put these building blocks together and customize them. Based on the configuration file, the platform will build a production model from raw data and automatically generate model performance report. This platform supports algorithms from classic linear model to most advanced machine learning model like gradient-boosting trees, deep neural networks, random forests, etc. It also support some advance techniques based on our research, such as ensemble modeling, which combine multiple models together to reach best results.
With MLP, data scientists can build complex non-linear model in hours, in contrast to days to weeks in the past.


